Parece que el sistema más extendido para hacer traducción de textos es el
XLIFF, formato estándar del grupo OASIS.
Este formato intenta acabar con el proceso de tener todos los documentos traducidos para todos los idiomas de forma separada.
Lo ideal entonces sería que se transformara la documentación pod a ese formato. Pero no he visto nada en las listas de correo sobre este tema. Se podría buscar un filtro para pasar de pod a xliff y luego hacer la conversión de XLIFF a pod. Pero no hay ningún módulo en Perl que haga este tipo de cosas. No hay ninguna referencia en las listas de correo o grupos de noticias de Perl a este formato, por lo que aún no está claro la ventaja de trabajar con este formato. Esto es para proponerlo a otros grupos (no anglosajones, claro) como proyecto a largo plazo.
Hay algunas herramientas ya hechas, como algunos editores y servidores para la centralización del trabajo de los traductores. He probado algunos y este es lo que he sacado en claro:
* Transolution. En Python. Editor de ficheros Xliff. No lee ficheros de texto (o al menos yo no lo he conseguido).
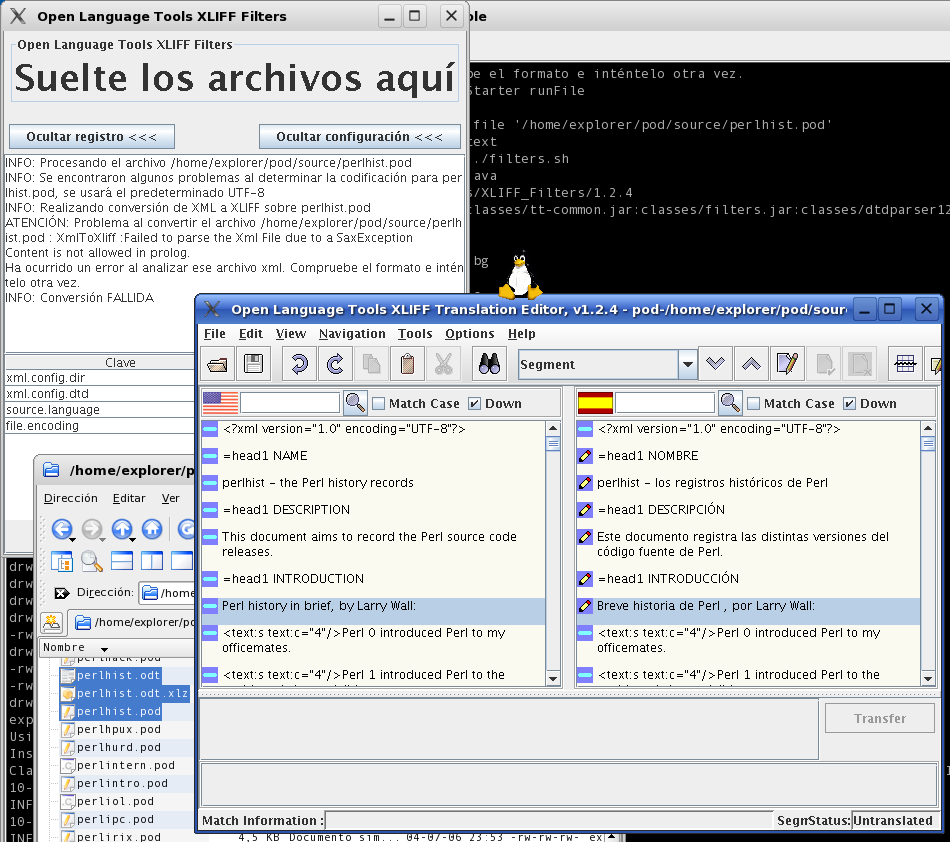
* Open Translator Tools. Está escrito en Java. Tiene filtros para pasar los ficheros a formato XLIFF y luego con el editor hacer la traducción. Los textos normales los pasa bien... pero no es capaz de distinguir los fichero pod. No es capaz de saber qué formato tienen y falla. Lo he conseguido pasando primero los ficheros pod a formato odt (openDocument de openoffice) y de allí con el filtro lo pasa a formato xlz (XLIFF comprimido) y de allí ya se pueden cargar y traducir. Lo que ya no he mirado es luego la forma de sacar la información del fichero XLIFF a formato pod normal, pero como es un fichero xml normal, se puede hacer con un filtro sin mucho problema... El verdadero problema es que todo esto es mucho trabajo.
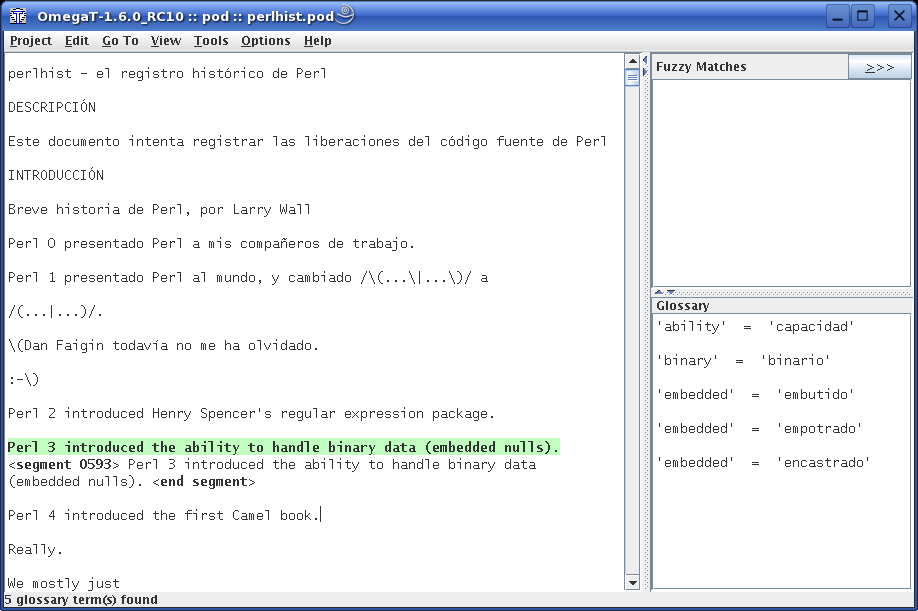
* OmegaT. Este es con el que mi siento más cómodo...
Ventajas:
* Es capaz de leer ficheros de texto normales.
* Puede hacer la división de segmentos del texto a nivel de frase.
* Reemplaza de forma automática frases ya traducidas antes.
* Propone frases y palabras ya traducidas antes con un cierto grado de semejanza.
* Análisis en background de los segmentos de todos los ficheros.
Desventajas:
* Está hecho en java. Tuve problemas al intentar agregar toda la documentación pod, pues se quedó sin memoria. Se arregló arrancando la máquina virtual de Java indicando que reservara más memoria.
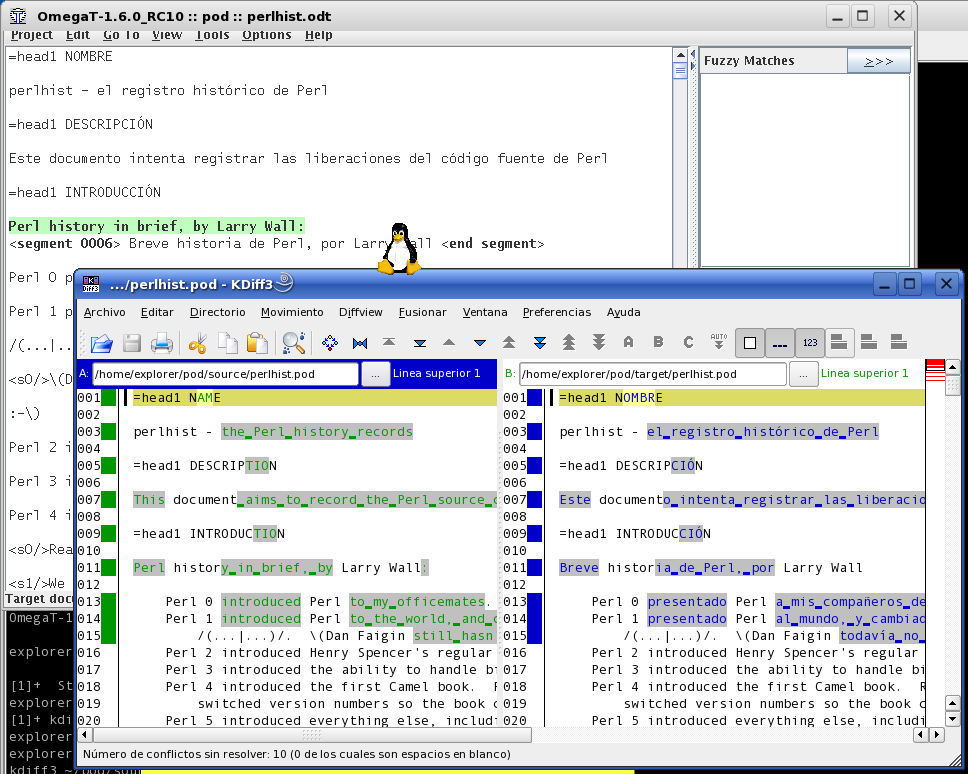
* No tiene control de versiones. Una vez traducidos los textos, deberíamos entonces usar diff para saber los cambios.
Aunque es un poco inestable (a veces se come toda la CPU), es lo más rápido que he visto para hacer las traducciones. Puedes crear un proyecto con algunos o todos los documentos que quieras traducir. Luego abres uno y vas traducciendo frase a frase. Si llega a una frase que ya has traducido (de forma exacta o algo parecida) te la coloca inmediatamente o te da varias sugerencias. Y en la ventana de glosario van saliendo las traducciones de las palabras que encuentra en el diccionario español-inglés que le he indicado (tengo uno de unas 24.000 palabras, pero seguro que tiene que haber otro con más palabras). Al final, le das para que genere los ficheros traducidos y te los deja en el directorio destino. Lo bueno (o malo) es que entonces mira fichero por fichero y va haciendo la traducción de todos los segmentos conocidos. Así, si en perlhist.pod (el primero que abrí), traduzco
=head1 NAME a
=head1 NOMBRE, este cambio lo hará en TODOS los documentos del directorio fuente.
Hay algunas herramientas más, en windows, pero ya no las he probado.
Sólo quedaría decidir...* Quién quiere participar y cómo. Además de traductores tienen que haber revisores de contenido y estilo. Una forma de hacerlo es que yo puedo traducir un documento, y otra persona (o mejor, más de una) hace la revisión, mientras que yo hago la revisión de su traducción...
* Lugar del proyecto (¿
pod2es.sourceforge.net? tienen de todo incluído cvs)
* Sistema de control de versiones de los textos originales en inglés. Tiene que quedar claro cuál ha de ser el procedimiento de trabajo. Por ejemplo:
1.- Hacer una primera copia de la última versión de la documentación en inglés.
2.- Seleccionar aquellos documentos que hemos elegido traducir.
3.- Los llevamos al directorio de origen de OmegaT y hacemos la traducción.
4.- Los subimos al repositorio común y actualizamos el número de versión del documento al mismo que tenía el original en inglés.
5.- En caso de repetir el ciclo: hay una nueva versión inglesa. Lo primero es averiguar las diferencias con la versión anterior. Un programa como kdiff3 o el simple diff pueden ayudar. De todas formas, con el OmegaT se puede incorporar el nuevo documento con otro nombre, con lo que hará la traducción inmediata de todos los segmentos anteriores y sólo tendremos que mirar los nuevos cambios.
De todas formas, no lo he mirado lo suficiente como para saber si es la herramienta perfecta para este trabajo... claro que siempre habrá alguno que quiera hacerlo 'a mano'.
Cuestiones pendientes:* Codificación que vamos a elegir... ISO-8859 o UTF8. Yo prefiero la segunda opción... OmegaT puede generar ficheros en un montón de codificaciones.
* Necesitamos a alguien con una PAUSE ID para publicar el paquete
POD2::ES en CPAN.
* idem, para comentar al webmaster de perldoc.org si existe la posibilidad de integrarlo en esa web.
* integración en perldoc -L ES...
* ... ¿?
¿Comentarios?